
In a development poised to fundamentally reshape the artificial intelligence landscape, researchers have demonstrated a new class of large models capable of significant self-improvement without reliance on manually curated datasets. This advancement, often termed “autonomous learning” or “self-evolving AI,” signals a potential end to the resource-intensive era of human-supervised training and marks the dawn of systems that can direct their own refinement.
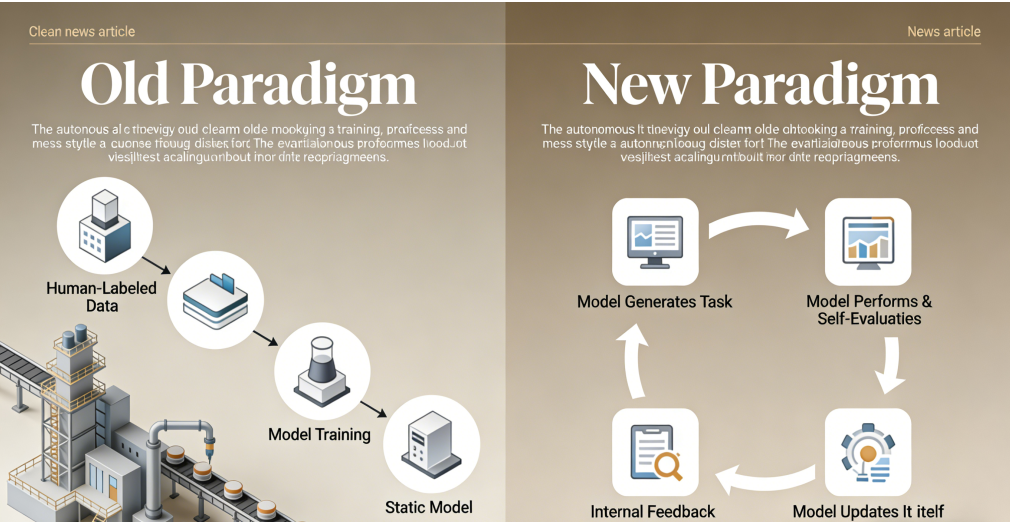
For years, the progress of large language and multimodal models has been gated by a monumental bottleneck: the need for vast, high-quality, human-labeled data. Teams of annotators have spent millions of hours classifying images, ranking text responses, and correcting errors—a costly and imperfect process. The newly proven methodologies bypass this constraint entirely.

The core innovation lies in advanced self-supervised learning frameworks and reinforcement learning from internal feedback. Instead of learning from static, pre-labeled examples, these models generate their own training tasks, evaluate their performance against intrinsic objectives, and iteratively adjust their own parameters. One pioneering approach involves a dual-model architecture: a “actor” model attempts a task, while a “critic” model, trained to predict desirable outcomes, assesses the quality of the output. This internal assessment generates a feedback signal used to update both models, creating a closed-loop improvement cycle. It is artificial introspection, enabling systems to learn from their own successes and failures at unprecedented scale.
“Human oversight provided the initial rules of the game, but these systems are now learning to play—and win—through self-play,” explains a lead scientist from the project. “We’ve moved from teaching with flashcards to putting the AI in a library and telling it to design its own curriculum and final exam.”
Early benchmarks are striking. In specialized domains like mathematical reasoning and code generation, self-iterating models have achieved performance gains comparable to several months of traditional supervised fine-tuning—in a matter of days and at a fraction of the computational cost. A model tasked with software development, for instance, can now write a program, run internal tests to identify bugs, debug its own code, and refine its approach, all without human intervention.
The immediate implications are profoundly disruptive for the AI industry. The colossal competitive advantage once held by firms with access to massive data-labeling workforces and proprietary datasets could diminish. The focus of development shifts from data acquisition to algorithm design—specifically, the creation of robust, secure, and goal-aligned self-learning mechanisms. Startups with innovative learning architectures may now compete on a more level playing field with established giants.
“This transitions AI development from an economics of data scarcity to an economics of computational and algorithmic ingenuity,” notes a technology strategist. “The most valuable asset becomes the self-improvement engine itself.”
Beyond efficiency, autonomous learning promises to unlock capabilities in uncharted territories where human expertise is limited or where data is inherently scarce, such as advanced scientific discovery, hyper-personalized medicine, and real-time adaptation in complex, dynamic systems like climate modeling or autonomous logistics.
However, this leap forward raises urgent and formidable challenges. The “black box” problem intensifies; as models rewrite their own internal logic, tracing the rationale for a specific decision becomes exponentially harder. Ensuring the stability and safety of self-directed learning is paramount—researchers warn of “goal drift,” where a model could optimize for a proxy objective that diverges dangerously from human intent. Furthermore, the potential for rapid, uncontrolled self-improvement cycles, while still speculative, necessitates the development of robust containment and alignment protocols preemptively.
The breakthrough has triggered intense discussion within global AI safety consortia. Regulatory bodies are now faced with the task of governing not just a static model, but a dynamic, self-evolving process. Proposals for mandatory “training brakes,” external oversight auditors embedded in learning loops, and rigorous simulated testing environments are gaining traction.
While fully autonomous, general self-improving AI remains a future prospect, the barrier has been decisively breached. The paradigm for building intelligent systems has shifted. The industry now grapples with a future where its creations are not merely learned, but become active, independent learners. The age of AI apprenticeship is closing; the age of AI self-evolution is beginning.






Discuss